-
Quick start
-
API
-
-
- Resume
- Add
- AdditiveAttention
- AlphaDropout
- Attention
- Average
- AvgPool1D
- AvgPool2D
- AvgPool3D
- BatchNormalization
- Bidirectional
- Concatenate
- Conv1D
- Conv1DTranspose
- Conv2D
- Conv2DTranspose
- Conv3D
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Cropping1D
- Cropping2D
- Cropping3D
- Dense
- DepthwiseConv2D
- Dropout
- ELU
- Embedding
- Exponential
- Flatten
- GaussianDropout
- GaussianNoise
- GELU
- GlobalAvgPool1D
- GlobalAvgPool2D
- GlobalAvgPool3D
- GlobalMaxPool1D
- GlobalMaxPool2D
- GlobalMaxPool3D
- GRU
- HardSigmoid
- Input
- LayerNormalization
- LeakyReLU
- Linear
- LSTM
- MaxPool1D
- MaxPool2D
- MaxPool3D
- MultiHeadAttention
- Multiply
- Output Predict
- Output Train
- Permute3D
- PReLU
- ReLU
- Reshape
- RNN
- SELU
- SeparableConv1D
- SeparableConv2D
- Sigmoid
- SimpleRNN
- SoftMax
- SoftPlus
- SoftSign
- SpatialDropout
- Split
- Substract
- Swish
- TanH
- ThresholdedReLU
- UpSampling1D
- UpSampling2D
- UpSampling3D
- ZeroPadding1D
- ZeroPadding2D
- ZeroPadding3D
- Show All Articles (64) Collapse Articles
-
-
-
-
- Abs
- Acos
- Acosh
- ArgMax
- ArgMin
- Asin
- Asinh
- Atan
- Atanh
- AveragePool
- Bernouilli
- BitwiseNot
- BlackmanWindow
- Cast
- Ceil
- Celu
- ConcatFromSequence
- Cos
- Cosh
- DepthToSpace
- Det
- DynamicTimeWarping
- Erf
- Exp
- EyeLike
- Flatten
- Floor
- GlobalAveragePool
- GlobalLpPool
- GlobalMaxPool
- HammingWindow
- HannWindow
- HardSwish
- HardMax
- Identity
- ImageDecoder
- Inverse
- lrfft
- lslnf
- lsNaN
- Log
- LogSoftmax
- LpNormalization
- LpPool
- LRN
- MeanVarianceNormalization
- MicrosoftGelu
- Mish
- Multinomial
- MurmurHash3
- Neg
- NhwcMaxPool
- NonZero
- Not
- OptionalGetElement
- OptionalHasElement
- QuickGelu
- RandomNormalLike
- RandomUniformLike
- RawConstantOfShape
- Reciprocal
- ReduceSumInteger
- RegexFullMatch
- Rfft
- Round
- SampleOp
- SequenceLength
- Shape
- Shrink
- Sign
- Sin
- Sinh
- Size
- SpaceToDepth
- Sqrt
- StringNormalizer
- Tan
- TfldfVectorizer
- Tokenizer
- Transpose
- UnfoldTensor
- Show All Articles (66) Collapse Articles
-
-
-
- Add
- AffineGrid
- And
- BiasAdd
- BiasGelu
- BiasSoftmax
- BiasSplitGelu
- BitShift
- BitwiseAnd
- BitwiseOr
- BitwiseXor
- CastLike
- CDist
- CenterCropPad
- Clip
- Col2lm
- ComplexMul
- ComplexMulConj
- Compress
- Conv
- ConvInteger
- ConvTranspose
- ConvTransposeWithDynamicPads
- CropAndResize
- CumSum
- DeformConv
- DequantizeBFP
- DequantizeLinear
- DequantizeWithOrder
- DFT
- Div
- DynamicQuantizeMatMul
- Equal
- Expand
- ExpandDims
- FastGelu
- FusedConv
- FusedGemm
- FusedMatMul
- FusedMatMulActivation
- GatedRelativePositionBias
- Gather
- GatherElements
- GatherND
- Gemm
- GemmFastGelu
- GemmFloat8
- Greater
- GreaterOrEqual
- GreedySearch
- GridSample
- GroupNorm
- InstanceNormalization
- Less
- LessOrEqual
- LongformerAttention
- MatMul
- MatMulBnb4
- MatMulFpQ4
- MatMulInteger
- MatMulInteger16
- MatMulIntergerToFloat
- MatMulNBits
- MaxPoolWithMask
- MaxRoiPool
- MaxUnPool
- MelWeightMatrix
- MicrosoftDequantizeLinear
- MicrosoftGatherND
- MicrosoftGridSample
- MicrosoftPad
- MicrosoftQLinearConv
- MicrosoftQuantizeLinear
- MicrosoftRange
- MicrosoftTrilu
- Mod
- MoE
- Mul
- MulInteger
- NegativeLogLikelihoodLoss
- NGramRepeatBlock
- NhwcConv
- NhwcFusedConv
- NonMaxSuppression
- OneHot
- Or
- PackedAttention
- PackedMultiHeadAttention
- Pad
- Pow
- QGemm
- QLinearAdd
- QLinearAveragePool
- QLinearConcat
- QLinearConv
- QLinearGlobalAveragePool
- QLinearLeakyRelu
- QLinearMatMul
- QLinearMul
- QLinearReduceMean
- QLinearSigmoid
- QLinearSoftmax
- QLinearWhere
- QMoE
- QOrderedAttention
- QOrderedGelu
- QOrderedLayerNormalization
- QOrderedLongformerAttention
- QOrderedMatMul
- QuantizeLinear
- QuantizeWithOrder
- Range
- ReduceL1
- ReduceL2
- ReduceLogSum
- ReduceLogSumExp
- ReduceMax
- ReduceMean
- ReduceMin
- ReduceProd
- ReduceSum
- ReduceSumSquare
- RelativePositionBias
- Reshape
- Resize
- RestorePadding
- ReverseSequence
- RoiAlign
- RotaryEmbedding
- ScatterElements
- ScatterND
- SequenceAt
- SequenceErase
- SequenceInsert
- Slice
- SparseToDenseMatMul
- SplitToSequence
- Squeeze
- STFT
- StringConcat
- Sub
- Tile
- TorchEmbedding
- TransposeMatMul
- Trilu
- Unsqueeze
- Where
- WordConvEmbedding
- Xor
- Show All Articles (134) Collapse Articles
-
- Attention
- AttnLSTM
- BatchNormalization
- BiasDropout
- BifurcationDetector
- BitmaskBiasDropout
- BitmaskDropout
- DecoderAttention
- DecoderMaskedMultiHeadAttention
- DecoderMaskedSelfAttention
- Dropout
- DynamicQuantizeLSTM
- EmbedLayerNormalization
- GemmaRotaryEmbedding
- GroupQueryAttention
- GRU
- LayerNormalization
- LSTM
- MicrosoftMultiHeadAttention
- QAttention
- RemovePadding
- RNN
- Sampling
- SkipGroupNorm
- SkipLayerNormalization
- SkipSimplifiedLayerNormalization
- SoftmaxCrossEntropyLoss
- SparseAttention
- TopK
- WhisperBeamSearch
- Show All Articles (15) Collapse Articles
-
-
-
-
-
-
- Resume
- Constant
- GlorotNormal
- GlorotUniform
- HeNormal
- HeUniform
- Identity
- LecunNormal
- LecunUniform
- Ones
- Orthogonal
- RandomNormal
- RandomUnifom
- TruncatedNormal
- VarianceScaling
- Zeros
- Show All Articles (1) Collapse Articles
-
- Resume
- BinaryCrossentropy
- CategoricalCrossentropy
- CategoricalHinge
- CosineSimilarity
- Hinge
- Huber
- KLDivergence
- LogCosh
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanSquaredError
- MeanSquaredLogarithmicError
- Poisson
- SquaredHinge
- Custom
- Show All Articles (1) Collapse Articles
-
-
-
-
-
- Dense
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- AdditiveAttention
- Attention
- MutiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- Embedding
- BatchNormalization
- LayerNormalization
- Bidirectional
- GRU
- LSTM
- SimpleRNN
- Show All Articles (12) Collapse Articles
-
- Dense
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- Embedding
- BatchNormalization
- LayerNormalization
- Bidirectional
- GRU
- LSTM
- SimpleRNN
- Show All Articles (12) Collapse Articles
-
-
- Resume
- Dense
- AdditiveAttention
- Attention
- MultiHeadAttention
- BatchNormalization
- LayerNormalization
- Bidirectional
- GRU
- LSTM
- SimpleRNN
- Conv1D
- Conv2D
- Conv3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- Embedding
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Show All Articles (13) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
-
- Resume
- Accuracy
- BinaryAccuracy
- BinaryCrossentropy
- BinaryIoU
- CategoricalAccuracy
- CategoricalCrossentropy
- CategoricalHinge
- CosineSimilarity
- FalseNegatives
- FalsePositives
- Hinge
- Huber
- IoU
- KLDivergence
- LogCoshError
- Mean
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanIoU
- MeanRelativeError
- MeanSquaredError
- MeanSquaredLogarithmicError
- MeanTensor
- OneHotIoU
- OneHotMeanIoU
- Poisson
- Precision
- PrecisionAtRecall
- Recall
- RecallAtPrecision
- RootMeanSquaredError
- SensitivityAtSpecificity
- SparseCategoricalAccuracy
- SparseCategoricalCrossentropy
- SparseTopKCategoricalAccuracy
- Specificity
- SpecificityAtSensitivity
- SquaredHinge
- Sum
- TopKCategoricalAccuracy
- TrueNegatives
- TruePositives
- Show All Articles (28) Collapse Articles
-
-
FusedMatMulActivation
Description
Executes the same operation as FusedMatMul, but also has an activation function fused to its output.
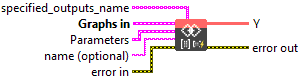
Input parameters
![]() specified_outputs_name : array, this parameter lets you manually assign custom names to the output tensors of a node.
specified_outputs_name : array, this parameter lets you manually assign custom names to the output tensors of a node.
![]() Graphs in : cluster, ONNX model architecture.
Graphs in : cluster, ONNX model architecture.
![]() A (heterogeneous) – T : object, N-dimensional matrix A.
A (heterogeneous) – T : object, N-dimensional matrix A.![]() B (heterogeneous) – T : object, N-dimensional matrix B.
B (heterogeneous) – T : object, N-dimensional matrix B.

![]() Parameters : cluster,
Parameters : cluster,
![]() activation : enum, activation function.
activation : enum, activation function.
Default value “Relu”.![]() activation_alpha : float, scalar parameter passed to the activation function. Used by activations that require one coefficient, such as LeakyRelu (negative slope α), Elu (α), or HardSigmoid (α). Ignored if not applicable.
activation_alpha : float, scalar parameter passed to the activation function. Used by activations that require one coefficient, such as LeakyRelu (negative slope α), Elu (α), or HardSigmoid (α). Ignored if not applicable.
Default value “0”.![]() activation_axis : float, axis parameter forwarded to activations that are axis-sensitive (e.g., Softmax, LogSoftmax, LayerNormalization). Defines the dimension along which the activation is applied. Ignored if not relevant.
activation_axis : float, axis parameter forwarded to activations that are axis-sensitive (e.g., Softmax, LogSoftmax, LayerNormalization). Defines the dimension along which the activation is applied. Ignored if not relevant.
Default value “0”.![]() activation_beta : float, scalar parameter forwarded to the activation when a second parameter is needed, such as HardSigmoid (β). Ignored if not applicable.
activation_beta : float, scalar parameter forwarded to the activation when a second parameter is needed, such as HardSigmoid (β). Ignored if not applicable.
Default value “0”.![]() activation_gamma : float, extra scalar parameter for activations that require a third value (e.g., certain scaled or shifted variants supported by specific execution providers). Ignored if not applicable.
activation_gamma : float, extra scalar parameter for activations that require a third value (e.g., certain scaled or shifted variants supported by specific execution providers). Ignored if not applicable.
Default value “0”.![]() alpha : float, scalar multiplier for the product of the input tensors.
alpha : float, scalar multiplier for the product of the input tensors.
Default value “0”.![]() transA : boolean, whether A should be transposed on the last two dimensions before doing multiplication.
transA : boolean, whether A should be transposed on the last two dimensions before doing multiplication.
Default value “False”.![]() transB : boolean, whether B should be transposed on the last two dimensions before doing multiplication.
transB : boolean, whether B should be transposed on the last two dimensions before doing multiplication.
Default value “False”.![]() transBatchA : boolean, whether A should be transposed on the 1st dimension and batch dimensions (dim-1 to dim-rank-2) before doing multiplication.
transBatchA : boolean, whether A should be transposed on the 1st dimension and batch dimensions (dim-1 to dim-rank-2) before doing multiplication.
Default value “False”.![]() transBatchB : boolean, whether B should be transposed on the 1st dimension and batch dimensions (dim-1 to dim-rank-2) before doing multiplication.
transBatchB : boolean, whether B should be transposed on the 1st dimension and batch dimensions (dim-1 to dim-rank-2) before doing multiplication.
Default value “False”.![]() training? : boolean, whether the layer is in training mode (can store data for backward).
training? : boolean, whether the layer is in training mode (can store data for backward).
Default value “True”.![]() lda coeff : float, defines the coefficient by which the loss derivative will be multiplied before being sent to the previous layer (since during the backward run we go backwards).
lda coeff : float, defines the coefficient by which the loss derivative will be multiplied before being sent to the previous layer (since during the backward run we go backwards).
Default value “1”.
![]() name (optional) : string, name of the node.
name (optional) : string, name of the node.

Output parameters
![]() Y (heterogeneous) – T : object, matrix multiply results.
Y (heterogeneous) – T : object, matrix multiply results.
Type Constraints
T in (tensor(float), tensor(float16), tensor(bfloat16), tensor(double)) : Constrain input and output types to float tensors.