-
Quick start
-
API
-
-
- Resume
- Add
- AdditiveAttention
- AlphaDropout
- Attention
- Average
- AvgPool1D
- AvgPool2D
- AvgPool3D
- BatchNormalization
- Bidirectional
- Concatenate
- Conv1D
- Conv1DTranspose
- Conv2D
- Conv2DTranspose
- Conv3D
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Cropping1D
- Cropping2D
- Cropping3D
- Dense
- DepthwiseConv2D
- Dropout
- ELU
- Embedding
- Exponential
- Flatten
- GaussianDropout
- GaussianNoise
- GELU
- GlobalAvgPool1D
- GlobalAvgPool2D
- GlobalAvgPool3D
- GlobalMaxPool1D
- GlobalMaxPool2D
- GlobalMaxPool3D
- GRU
- HardSigmoid
- Input
- LayerNormalization
- LeakyReLU
- Linear
- LSTM
- MaxPool1D
- MaxPool2D
- MaxPool3D
- MultiHeadAttention
- Multiply
- Output Predict
- Output Train
- Permute3D
- PReLU
- ReLU
- Reshape
- RNN
- SELU
- SeparableConv1D
- SeparableConv2D
- Sigmoid
- SimpleRNN
- SoftMax
- SoftPlus
- SoftSign
- SpatialDropout
- Split
- Substract
- Swish
- TanH
- ThresholdedReLU
- UpSampling1D
- UpSampling2D
- UpSampling3D
- ZeroPadding1D
- ZeroPadding2D
- ZeroPadding3D
- Show All Articles (64) Collapse Articles
-
-
-
-
- Abs
- Acos
- Acosh
- ArgMax
- ArgMin
- Asin
- Asinh
- Atan
- Atanh
- AveragePool
- Bernouilli
- BitwiseNot
- BlackmanWindow
- Cast
- Ceil
- Celu
- ConcatFromSequence
- Cos
- Cosh
- DepthToSpace
- Det
- DynamicTimeWarping
- Erf
- Exp
- EyeLike
- Flatten
- Floor
- GlobalAveragePool
- GlobalLpPool
- GlobalMaxPool
- HammingWindow
- HannWindow
- HardSwish
- HardMax
- Identity
- ImageDecoder
- Inverse
- lrfft
- lslnf
- lsNaN
- Log
- LogSoftmax
- LpNormalization
- LpPool
- LRN
- MeanVarianceNormalization
- MicrosoftGelu
- Mish
- Multinomial
- MurmurHash3
- Neg
- NhwcMaxPool
- NonZero
- Not
- OptionalGetElement
- OptionalHasElement
- QuickGelu
- RandomNormalLike
- RandomUniformLike
- RawConstantOfShape
- Reciprocal
- ReduceSumInteger
- RegexFullMatch
- Rfft
- Round
- SampleOp
- SequenceLength
- Shape
- Shrink
- Sign
- Sin
- Sinh
- Size
- SpaceToDepth
- Sqrt
- StringNormalizer
- Tan
- TfldfVectorizer
- Tokenizer
- Transpose
- UnfoldTensor
- Show All Articles (66) Collapse Articles
-
-
-
- Add
- AffineGrid
- And
- BiasAdd
- BiasGelu
- BiasSoftmax
- BiasSplitGelu
- BitShift
- BitwiseAnd
- BitwiseOr
- BitwiseXor
- CastLike
- CDist
- CenterCropPad
- Clip
- Col2lm
- ComplexMul
- ComplexMulConj
- Compress
- Conv
- ConvInteger
- ConvTranspose
- ConvTransposeWithDynamicPads
- CropAndResize
- CumSum
- DeformConv
- DequantizeBFP
- DequantizeLinear
- DequantizeWithOrder
- DFT
- Div
- DynamicQuantizeMatMul
- Equal
- Expand
- ExpandDims
- FastGelu
- FusedConv
- FusedGemm
- FusedMatMul
- FusedMatMulActivation
- GatedRelativePositionBias
- Gather
- GatherElements
- GatherND
- Gemm
- GemmFastGelu
- GemmFloat8
- Greater
- GreaterOrEqual
- GreedySearch
- GridSample
- GroupNorm
- InstanceNormalization
- Less
- LessOrEqual
- LongformerAttention
- MatMul
- MatMulBnb4
- MatMulFpQ4
- MatMulInteger
- MatMulInteger16
- MatMulIntergerToFloat
- MatMulNBits
- MaxPoolWithMask
- MaxRoiPool
- MaxUnPool
- MelWeightMatrix
- MicrosoftDequantizeLinear
- MicrosoftGatherND
- MicrosoftGridSample
- MicrosoftPad
- MicrosoftQLinearConv
- MicrosoftQuantizeLinear
- MicrosoftRange
- MicrosoftTrilu
- Mod
- MoE
- Mul
- MulInteger
- NegativeLogLikelihoodLoss
- NGramRepeatBlock
- NhwcConv
- NhwcFusedConv
- NonMaxSuppression
- OneHot
- Or
- PackedAttention
- PackedMultiHeadAttention
- Pad
- Pow
- QGemm
- QLinearAdd
- QLinearAveragePool
- QLinearConcat
- QLinearConv
- QLinearGlobalAveragePool
- QLinearLeakyRelu
- QLinearMatMul
- QLinearMul
- QLinearReduceMean
- QLinearSigmoid
- QLinearSoftmax
- QLinearWhere
- QMoE
- QOrderedAttention
- QOrderedGelu
- QOrderedLayerNormalization
- QOrderedLongformerAttention
- QOrderedMatMul
- QuantizeLinear
- QuantizeWithOrder
- Range
- ReduceL1
- ReduceL2
- ReduceLogSum
- ReduceLogSumExp
- ReduceMax
- ReduceMean
- ReduceMin
- ReduceProd
- ReduceSum
- ReduceSumSquare
- RelativePositionBias
- Reshape
- Resize
- RestorePadding
- ReverseSequence
- RoiAlign
- RotaryEmbedding
- ScatterElements
- ScatterND
- SequenceAt
- SequenceErase
- SequenceInsert
- Slice
- SparseToDenseMatMul
- SplitToSequence
- Squeeze
- STFT
- StringConcat
- Sub
- Tile
- TorchEmbedding
- TransposeMatMul
- Trilu
- Unsqueeze
- Where
- WordConvEmbedding
- Xor
- Show All Articles (134) Collapse Articles
-
- Attention
- AttnLSTM
- BatchNormalization
- BiasDropout
- BifurcationDetector
- BitmaskBiasDropout
- BitmaskDropout
- DecoderAttention
- DecoderMaskedMultiHeadAttention
- DecoderMaskedSelfAttention
- Dropout
- DynamicQuantizeLSTM
- EmbedLayerNormalization
- GemmaRotaryEmbedding
- GroupQueryAttention
- GRU
- LayerNormalization
- LSTM
- MicrosoftMultiHeadAttention
- QAttention
- RemovePadding
- RNN
- Sampling
- SkipGroupNorm
- SkipLayerNormalization
- SkipSimplifiedLayerNormalization
- SoftmaxCrossEntropyLoss
- SparseAttention
- TopK
- WhisperBeamSearch
- Show All Articles (15) Collapse Articles
-
-
-
-
-
-
- Resume
- Constant
- GlorotNormal
- GlorotUniform
- HeNormal
- HeUniform
- Identity
- LecunNormal
- LecunUniform
- Ones
- Orthogonal
- RandomNormal
- RandomUnifom
- TruncatedNormal
- VarianceScaling
- Zeros
- Show All Articles (1) Collapse Articles
-
- Resume
- BinaryCrossentropy
- CategoricalCrossentropy
- CategoricalHinge
- CosineSimilarity
- Hinge
- Huber
- KLDivergence
- LogCosh
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanSquaredError
- MeanSquaredLogarithmicError
- Poisson
- SquaredHinge
- Custom
- Show All Articles (1) Collapse Articles
-
-
-
-
-
- Dense
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- AdditiveAttention
- Attention
- MutiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- Embedding
- BatchNormalization
- LayerNormalization
- Bidirectional
- GRU
- LSTM
- SimpleRNN
- Show All Articles (12) Collapse Articles
-
- Dense
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- Embedding
- BatchNormalization
- LayerNormalization
- Bidirectional
- GRU
- LSTM
- SimpleRNN
- Show All Articles (12) Collapse Articles
-
-
- Resume
- Dense
- AdditiveAttention
- Attention
- MultiHeadAttention
- BatchNormalization
- LayerNormalization
- Bidirectional
- GRU
- LSTM
- SimpleRNN
- Conv1D
- Conv2D
- Conv3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- Embedding
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Show All Articles (13) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
-
- Resume
- Accuracy
- BinaryAccuracy
- BinaryCrossentropy
- BinaryIoU
- CategoricalAccuracy
- CategoricalCrossentropy
- CategoricalHinge
- CosineSimilarity
- FalseNegatives
- FalsePositives
- Hinge
- Huber
- IoU
- KLDivergence
- LogCoshError
- Mean
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanIoU
- MeanRelativeError
- MeanSquaredError
- MeanSquaredLogarithmicError
- MeanTensor
- OneHotIoU
- OneHotMeanIoU
- Poisson
- Precision
- PrecisionAtRecall
- Recall
- RecallAtPrecision
- RootMeanSquaredError
- SensitivityAtSpecificity
- SparseCategoricalAccuracy
- SparseCategoricalCrossentropy
- SparseTopKCategoricalAccuracy
- Specificity
- SpecificityAtSensitivity
- SquaredHinge
- Sum
- TopKCategoricalAccuracy
- TrueNegatives
- TruePositives
- Show All Articles (28) Collapse Articles
-
-
DequantizeBFP
Description
The BFP dequantization operator. It consumes the raw BFP data and some metadata such as the shape and strides of the original tensor and computes the dequantized tensor. More documentation on the BFP format can be found in this paper: https://www.microsoft.com/en-us/research/publication/pushing-the-limits-of-narrow-precision-inferencing-at-cloud-scale-with-microsoft-floating-point/
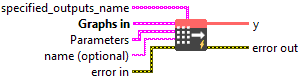
Input parameters
![]() specified_outputs_name : array, this parameter lets you manually assign custom names to the output tensors of a node.
specified_outputs_name : array, this parameter lets you manually assign custom names to the output tensors of a node.
![]() Graphs in : cluster, ONNX model architecture.
Graphs in : cluster, ONNX model architecture.
![]() x (heterogeneous) – T1 : object, 1-D, contiguous, raw, BFP data to be de-quantized.
x (heterogeneous) – T1 : object, 1-D, contiguous, raw, BFP data to be de-quantized.![]() shape (heterogeneous) – T2 : object, shape of the original tensor.
shape (heterogeneous) – T2 : object, shape of the original tensor.![]() strides (heterogeneous) – T2 : object, strides of the original tensor.
strides (heterogeneous) – T2 : object, strides of the original tensor.

![]() Parameters : cluster,
Parameters : cluster,
![]() bfp_type : enum, the type of BFP – must match with the BFPType enum.
bfp_type : enum, the type of BFP – must match with the BFPType enum.
Default value “UNDEFINED”.![]() block_dim : float, each bounding box spans this dimension.Typically, the block dimension corresponds to the reduction dimension of the matrix multipication that consumes the output of this operator.For example, for a 2D matrix multiplication A@W, QuantizeBFP(A) would use block_dim 1 and QuantizeBFP(W) would use block_dim 0.The default is the last dimension.
block_dim : float, each bounding box spans this dimension.Typically, the block dimension corresponds to the reduction dimension of the matrix multipication that consumes the output of this operator.For example, for a 2D matrix multiplication A@W, QuantizeBFP(A) would use block_dim 1 and QuantizeBFP(W) would use block_dim 0.The default is the last dimension.
Default value “0”.![]() dtype : enum, the datatype to dequantize to.
dtype : enum, the datatype to dequantize to.
Default value “UNDEFINED”.![]() training? : boolean, whether the layer is in training mode (can store data for backward).
training? : boolean, whether the layer is in training mode (can store data for backward).
Default value “True”.![]() lda coeff : float, defines the coefficient by which the loss derivative will be multiplied before being sent to the previous layer (since during the backward run we go backwards).
lda coeff : float, defines the coefficient by which the loss derivative will be multiplied before being sent to the previous layer (since during the backward run we go backwards).
Default value “1”.
![]() name (optional) : string, name of the node.
name (optional) : string, name of the node.

Output parameters
![]() y (heterogeneous) – T3 : object, de-quantized tensor.
y (heterogeneous) – T3 : object, de-quantized tensor.
Type Constraints
tensor(uint8)) : Constrain the input to uint8.
T2 in (tensor(int64)) : Constrain shape and strides to uint64.
T3 in (tensor(float), tensor(float16), tensor(bfloat16)) : Constrain y to float and bfloat16.