-
Quick start
-
API
-
-
- Resume
- Add
- AdditiveAttention
- AlphaDropout
- Attention
- Average
- AvgPool1D
- AvgPool2D
- AvgPool3D
- BatchNormalization
- Bidirectional
- Concatenate
- Conv1D
- Conv1DTranspose
- Conv2D
- Conv2DTranspose
- Conv3D
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Cropping1D
- Cropping2D
- Cropping3D
- Dense
- DepthwiseConv2D
- Dropout
- ELU
- Embedding
- Exponential
- Flatten
- GaussianDropout
- GaussianNoise
- GELU
- GlobalAvgPool1D
- GlobalAvgPool2D
- GlobalAvgPool3D
- GlobalMaxPool1D
- GlobalMaxPool2D
- GlobalMaxPool3D
- GRU
- HardSigmoid
- Input
- LayerNormalization
- LeakyReLU
- Linear
- LSTM
- MaxPool1D
- MaxPool2D
- MaxPool3D
- MultiHeadAttention
- Multiply
- Output Predict
- Output Train
- Permute3D
- PReLU
- ReLU
- Reshape
- RNN
- SELU
- SeparableConv1D
- SeparableConv2D
- Sigmoid
- SimpleRNN
- SoftMax
- SoftPlus
- SoftSign
- SpatialDropout
- Split
- Substract
- Swish
- TanH
- ThresholdedReLU
- UpSampling1D
- UpSampling2D
- UpSampling3D
- ZeroPadding1D
- ZeroPadding2D
- ZeroPadding3D
- Show All Articles (64) Collapse Articles
-
-
-
-
- Abs
- Acos
- Acosh
- ArgMax
- ArgMin
- Asin
- Asinh
- Atan
- Atanh
- AveragePool
- Bernouilli
- BitwiseNot
- BlackmanWindow
- Cast
- Ceil
- Celu
- ConcatFromSequence
- Cos
- Cosh
- DepthToSpace
- Det
- DynamicTimeWarping
- Erf
- Exp
- EyeLike
- Flatten
- Floor
- GlobalAveragePool
- GlobalLpPool
- GlobalMaxPool
- HammingWindow
- HannWindow
- HardSwish
- HardMax
- Identity
- ImageDecoder
- Inverse
- lrfft
- lslnf
- lsNaN
- Log
- LogSoftmax
- LpNormalization
- LpPool
- LRN
- MeanVarianceNormalization
- MicrosoftGelu
- Mish
- Multinomial
- MurmurHash3
- Neg
- NhwcMaxPool
- NonZero
- Not
- OptionalGetElement
- OptionalHasElement
- QuickGelu
- RandomNormalLike
- RandomUniformLike
- RawConstantOfShape
- Reciprocal
- ReduceSumInteger
- RegexFullMatch
- Rfft
- Round
- SampleOp
- SequenceLength
- Shape
- Shrink
- Sign
- Sin
- Sinh
- Size
- SpaceToDepth
- Sqrt
- StringNormalizer
- Tan
- TfldfVectorizer
- Tokenizer
- Transpose
- UnfoldTensor
- Show All Articles (66) Collapse Articles
-
-
-
- Add
- AffineGrid
- And
- BiasAdd
- BiasGelu
- BiasSoftmax
- BiasSplitGelu
- BitShift
- BitwiseAnd
- BitwiseOr
- BitwiseXor
- CastLike
- CDist
- CenterCropPad
- Clip
- Col2lm
- ComplexMul
- ComplexMulConj
- Compress
- Conv
- ConvInteger
- ConvTranspose
- ConvTransposeWithDynamicPads
- CropAndResize
- CumSum
- DeformConv
- DequantizeBFP
- DequantizeLinear
- DequantizeWithOrder
- DFT
- Div
- DynamicQuantizeMatMul
- Equal
- Expand
- ExpandDims
- FastGelu
- FusedConv
- FusedGemm
- FusedMatMul
- FusedMatMulActivation
- GatedRelativePositionBias
- Gather
- GatherElements
- GatherND
- Gemm
- GemmFastGelu
- GemmFloat8
- Greater
- GreaterOrEqual
- GreedySearch
- GridSample
- GroupNorm
- InstanceNormalization
- Less
- LessOrEqual
- LongformerAttention
- MatMul
- MatMulBnb4
- MatMulFpQ4
- MatMulInteger
- MatMulInteger16
- MatMulIntergerToFloat
- MatMulNBits
- MaxPoolWithMask
- MaxRoiPool
- MaxUnPool
- MelWeightMatrix
- MicrosoftDequantizeLinear
- MicrosoftGatherND
- MicrosoftGridSample
- MicrosoftPad
- MicrosoftQLinearConv
- MicrosoftQuantizeLinear
- MicrosoftRange
- MicrosoftTrilu
- Mod
- MoE
- Mul
- MulInteger
- NegativeLogLikelihoodLoss
- NGramRepeatBlock
- NhwcConv
- NhwcFusedConv
- NonMaxSuppression
- OneHot
- Or
- PackedAttention
- PackedMultiHeadAttention
- Pad
- Pow
- QGemm
- QLinearAdd
- QLinearAveragePool
- QLinearConcat
- QLinearConv
- QLinearGlobalAveragePool
- QLinearLeakyRelu
- QLinearMatMul
- QLinearMul
- QLinearReduceMean
- QLinearSigmoid
- QLinearSoftmax
- QLinearWhere
- QMoE
- QOrderedAttention
- QOrderedGelu
- QOrderedLayerNormalization
- QOrderedLongformerAttention
- QOrderedMatMul
- QuantizeLinear
- QuantizeWithOrder
- Range
- ReduceL1
- ReduceL2
- ReduceLogSum
- ReduceLogSumExp
- ReduceMax
- ReduceMean
- ReduceMin
- ReduceProd
- ReduceSum
- ReduceSumSquare
- RelativePositionBias
- Reshape
- Resize
- RestorePadding
- ReverseSequence
- RoiAlign
- RotaryEmbedding
- ScatterElements
- ScatterND
- SequenceAt
- SequenceErase
- SequenceInsert
- Slice
- SparseToDenseMatMul
- SplitToSequence
- Squeeze
- STFT
- StringConcat
- Sub
- Tile
- TorchEmbedding
- TransposeMatMul
- Trilu
- Unsqueeze
- Where
- WordConvEmbedding
- Xor
- Show All Articles (134) Collapse Articles
-
- Attention
- AttnLSTM
- BatchNormalization
- BiasDropout
- BifurcationDetector
- BitmaskBiasDropout
- BitmaskDropout
- DecoderAttention
- DecoderMaskedMultiHeadAttention
- DecoderMaskedSelfAttention
- Dropout
- DynamicQuantizeLSTM
- EmbedLayerNormalization
- GemmaRotaryEmbedding
- GroupQueryAttention
- GRU
- LayerNormalization
- LSTM
- MicrosoftMultiHeadAttention
- QAttention
- RemovePadding
- RNN
- Sampling
- SkipGroupNorm
- SkipLayerNormalization
- SkipSimplifiedLayerNormalization
- SoftmaxCrossEntropyLoss
- SparseAttention
- TopK
- WhisperBeamSearch
- Show All Articles (15) Collapse Articles
-
-
-
-
-
-
- Resume
- Constant
- GlorotNormal
- GlorotUniform
- HeNormal
- HeUniform
- Identity
- LecunNormal
- LecunUniform
- Ones
- Orthogonal
- RandomNormal
- RandomUnifom
- TruncatedNormal
- VarianceScaling
- Zeros
- Show All Articles (1) Collapse Articles
-
- Resume
- BinaryCrossentropy
- CategoricalCrossentropy
- CategoricalHinge
- CosineSimilarity
- Hinge
- Huber
- KLDivergence
- LogCosh
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanSquaredError
- MeanSquaredLogarithmicError
- Poisson
- SquaredHinge
- Custom
- Show All Articles (1) Collapse Articles
-
-
-
-
-
- Dense
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- AdditiveAttention
- Attention
- MutiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- Embedding
- BatchNormalization
- LayerNormalization
- Bidirectional
- GRU
- LSTM
- SimpleRNN
- Show All Articles (12) Collapse Articles
-
- Dense
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- Embedding
- BatchNormalization
- LayerNormalization
- Bidirectional
- GRU
- LSTM
- SimpleRNN
- Show All Articles (12) Collapse Articles
-
-
- Resume
- Dense
- AdditiveAttention
- Attention
- MultiHeadAttention
- BatchNormalization
- LayerNormalization
- Bidirectional
- GRU
- LSTM
- SimpleRNN
- Conv1D
- Conv2D
- Conv3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- Embedding
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Show All Articles (13) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (15) Collapse Articles
-
-
- Resume
- Accuracy
- BinaryAccuracy
- BinaryCrossentropy
- BinaryIoU
- CategoricalAccuracy
- CategoricalCrossentropy
- CategoricalHinge
- CosineSimilarity
- FalseNegatives
- FalsePositives
- Hinge
- Huber
- IoU
- KLDivergence
- LogCoshError
- Mean
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanIoU
- MeanRelativeError
- MeanSquaredError
- MeanSquaredLogarithmicError
- MeanTensor
- OneHotIoU
- OneHotMeanIoU
- Poisson
- Precision
- PrecisionAtRecall
- Recall
- RecallAtPrecision
- RootMeanSquaredError
- SensitivityAtSpecificity
- SparseCategoricalAccuracy
- SparseCategoricalCrossentropy
- SparseTopKCategoricalAccuracy
- Specificity
- SpecificityAtSensitivity
- SquaredHinge
- Sum
- TopKCategoricalAccuracy
- TrueNegatives
- TruePositives
- Show All Articles (28) Collapse Articles
-
-
Cast
Description
The operator casts the elements of a given input tensor to a data type specified by the ‘to’ argument and returns an output tensor of the same size in the converted type. The ‘to’ argument must be one of the data types specified in the ‘DataType’ enum field in the TensorProto message.
Casting from string tensor in plain (e.g., “3.14” and “1000”) and scientific numeric representations (e.g., “1e-5” and “1E8”) to float types is supported. For example, converting string “100.5” to an integer may yield result 100. There are some string literals reserved for special floating-point values; “+INF” (and “INF”), “-INF”, and “NaN” are positive infinity, negative infinity, and not-a-number, respectively. Any string which can exactly match “+INF” in a case-insensitive way would be mapped to positive infinite. Similarly, this case-insensitive rule is applied to “INF” and “NaN”. When casting from numeric tensors to string tensors, plain floating-point representation (such as “314.15926”) would be used. Converting non-numerical-literal string such as “Hello World!” is an undefined behavior. Cases of converting string representing floating-point arithmetic value, such as “2.718”, to INT is an undefined behavior.
Conversion from a numerical type to any numerical type is always allowed. User must be aware of precision loss and value change caused by range difference between two types. For example, a 64-bit float 3.1415926459 may be round to a 32-bit float 3.141592. Similarly, converting an integer 36 to Boolean may produce 1 because we truncate bits which can’t be stored in the targeted type.
In more detail, the conversion among numerical types should follow these rules if the destination type is not a float 8 type.
- Casting from floating point to:
- floating point: +/- infinity if OOR (out of range).
- fixed point: undefined if OOR.
- bool: +/- 0.0 to False; all else to True.
- Casting from fixed point to:
- floating point: +/- infinity if OOR. (+ infinity in the case of uint)
- fixed point: when OOR, discard higher bits and reinterpret (with respect to two’s complement representation for signed types). For example, 200 (int16) -> -56 (int8).
- bool: zero to False; nonzero to True.
- Casting from bool to:
- floating point:
{1.0, 0.0}. - fixed point:
{1, 0}. - bool: no change.
- floating point:
Float 8 type were introduced to speed up the training of deep models. By default the conversion of a float x obeys to the following rules. [x] means the value rounded to the target mantissa width.
| x | E4M3FN | E4M3FNUZ | E5M2 | E5M2FNUZ |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| -0 | -0 | 0 | -0 | 0 |
| NaN | NaN | NaN | NaN | NaN |
| Inf | FLT_MAX | NaN | FLT_MAX | NaN |
| -Inf | -FLT_MAX | NaN | -FLT_MAX | NaN |
| [x] > FLT_MAX | FLT_MAX | FLT_MAX | FLT_MAX | FLT_MAX |
| [x] < -FLT_MAX | -FLT_MAX | -FLT_MAX | -FLT_MAX | -FLT_MAX |
| else | RNE | RNE | RNE | RNE |
The behavior changes if the parameter ‘saturate’ is set to False. The rules then become :
| x | E4M3FN | E4M3FNUZ | E5M2 | E5M2FNUZ |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| -0 | -0 | 0 | -0 | 0 |
| NaN | NaN | NaN | NaN | NaN |
| -NaN | -NaN | NaN | -NaN | NaN |
| Inf | NaN | NaN | Inf | NaN |
| -Inf | -NaN | NaN | -Inf | NaN |
| [x] > FLT_MAX | NaN | NaN | Inf | NaN |
| [x] < -FLT_MAX | NaN | NaN | -Inf | NaN |
| else | RNE | RNE | RNE | RNE |
Input parameters
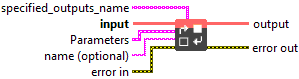
![]() specified_outputs_name : array, this parameter lets you manually assign custom names to the output tensors of a node.
specified_outputs_name : array, this parameter lets you manually assign custom names to the output tensors of a node.![]() input (heterogeneous) – T1 : object, input tensor to be cast.
input (heterogeneous) – T1 : object, input tensor to be cast.
![]() Parameters : cluster,
Parameters : cluster,
![]() saturate : boolean, the parameter defines how the conversion behaves if an input value is out of range of the destination type. It only applies for float 8 conversion (float8e4m3fn, float8e4m3fnuz, float8e5m2, float8e5m2fnuz). All cases are fully described in two tables inserted in the operator description.
saturate : boolean, the parameter defines how the conversion behaves if an input value is out of range of the destination type. It only applies for float 8 conversion (float8e4m3fn, float8e4m3fnuz, float8e5m2, float8e5m2fnuz). All cases are fully described in two tables inserted in the operator description.
Default value “True”.![]() to : enum, the data type to which the elements of the input tensor are cast. Strictly must be one of the types from DataType enum in TensorProto.
to : enum, the data type to which the elements of the input tensor are cast. Strictly must be one of the types from DataType enum in TensorProto.
Default value “UNDEFINED”.![]() training? : boolean, whether the layer is in training mode (can store data for backward).
training? : boolean, whether the layer is in training mode (can store data for backward).
Default value “True”.![]() lda coeff : float, defines the coefficient by which the loss derivative will be multiplied before being sent to the previous layer (since during the backward run we go backwards).
lda coeff : float, defines the coefficient by which the loss derivative will be multiplied before being sent to the previous layer (since during the backward run we go backwards).
Default value “1”.
![]() name (optional) : string, name of the node.
name (optional) : string, name of the node.

Output parameters
![]() output (heterogeneous) – T2 : object, output tensor with the same shape as input with type specified by the ‘to’ argument.
output (heterogeneous) – T2 : object, output tensor with the same shape as input with type specified by the ‘to’ argument.
Type Constraints
T1 in (tensor(bfloat16), tensor(bool), tensor(double), tensor(float), tensor(float16), tensor(float8e4m3fn),tensor(float8e4m3fnuz), tensor(float8e5m2), tensor(float8e5m2fnuz), tensor(int16), tensor(int32), tensor(int64), tensor(int8), tensor(string), tensor(uint16), tensor(uint32), tensor(uint64), tensor(uint8)) : Constrain input types. Casting from complex is not supported.
T2 in (tensor(bfloat16), tensor(bool), tensor(double), tensor(float), tensor(float16), tensor(float8e4m3fn),tensor(float8e4m3fnuz), tensor(float8e5m2), tensor(float8e5m2fnuz), tensor(int16), tensor(int32), tensor(int64), tensor(int8), tensor(string), tensor(uint16), tensor(uint32), tensor(uint64), tensor(uint8)) : Constrain output types. Casting to complex is not supported.